
¿Qué es el Robots.txt?
El archivo robots.txt es un archivo utilizado para indicar a los motores de búsqueda (como Google, Bing, etc.) qué páginas o secciones de un sitio web deben de ser excluidas de sus índices.
Esto es útil si hay secciones de un sitio que no se quiere que sean encontradas por los motores de búsqueda, como páginas de prueba o páginas antiguas que ya no son relevantes.
¿Dónde se encuentra el Robots.txt?
El archivo robots.txt se coloca en la raíz del sitio web y puede ser utilizado para especificar las directivas para diferentes motores de búsqueda.
Por ejemplo, se puede utilizar para decirle a Google que no indexe ciertas páginas, pero permitir que Bing lo haga.
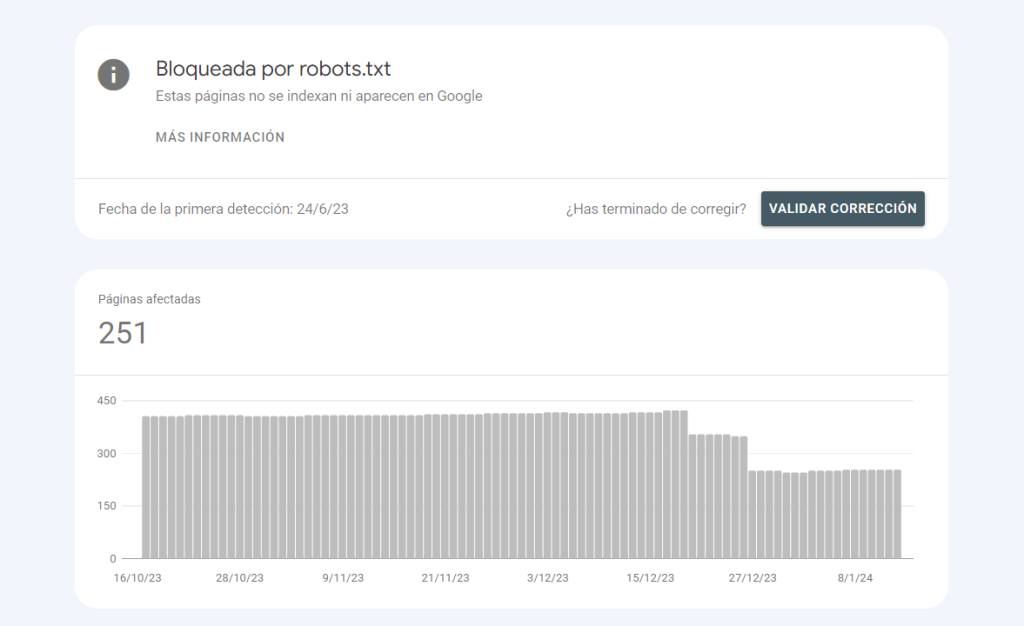
Es importante tener en cuenta que el archivo robots.txt no es una medida de seguridad y no impide que los motores de búsqueda accedan a las páginas excluidas.
Si un motor de búsqueda encuentra un enlace a una página excluida en el archivo robots.txt, es posible que aún intente acceder a esa página.

Por lo tanto, el archivo robots.txt es más adecuado para excluir páginas que no se quieren que sean encontradas por los motores de búsqueda, pero que no son sensibles o confidenciales.
¿Cómo funciona un archivo robots.txt?
Para utilizar el archivo robots.txt, se debe crear un archivo de texto plano y colocarlo en la raíz del sitio web.
Luego se deben añadir las directivas para los diferentes motores de búsqueda. Cada línea del archivo robots.txt contiene una directiva y una lista de URLs a las que se aplica la directiva.
Las directivas más comunes son «Allow» y «Disallow», que permiten o excluyen, respectivamente, el acceso a las URLs especificadas.
Es importante tener en cuenta que el archivo robots.txt no es un archivo oficial y no está respaldado por los estándares de internet.
Los motores de búsqueda pueden elegir ignorar las directivas del archivo robots.txt o pueden cambiar su forma de interpretar las directivas en el futuro.
Por lo tanto, el archivo robots.txt debe utilizarse con precaución y no debe dependerse de él para excluir páginas sensibles o confidenciales del índice de los motores de búsqueda.

