Tienes un ecommerce. En la agencia vemos ecommerces a diario, somos expertos en SEO para ecommerce, ¿recuerdas? bueno al lío que nos perdemos… 🙂
Subes productos nuevos, optimizas sus descripciones, sacas fotos espectaculares. Entras a Google Search Console y ves que la actividad de rastreo está por las nubes: «Googlebot está trabajando», piensas. Pero tus productos nuevos siguen sin indexarse y el tráfico no llega.
¿Qué está pasando? Estás sufriendo el problema de la fuga de presupuesto de rastreo por navegación facetada, es decir, Googlebot está perdiendo el tiempo en otras cosas (el crawl budget es limitado).
Es como si invitas a Googlebot a tu almacén para que vea tu nueva mercancía (tus productos), pero por el camino lo dejas suelto en una sala llena de botones, palancas y luces de colores (tus filtros de talla, color, marca, precio…). Googlebot, no olvides que es un crawler y su obligación es rastrear todo lo que encuentre, se queda fascinado jugando con los botones, creando miles de combinaciones, y nunca llega a ver la mercancía que de verdad importa.
Los logs del servidor no mienten. Son el vídeo de seguridad que te muestra a Googlebot atrapado en la sala de juegos en lugar de estar en el almacén. Hoy vamos a usar esos logs para pillarlo con las manos en la masa y guiarlo hacia donde tiene que ir.
La evidencia del crimen: tus logs te están gritando el problema
La navegación facetada (los filtros) es genial para los usuarios, pero es veneno para el SEO si no se controla. Cada vez que un bot hace clic en un filtro, genera una nueva URL con un parámetro: ?color=azul, ?talla=42, ?marca=acme. Cuando combinas varios, creas un monstruo:
.../zapatillas?color=azul&talla=42&marca=acme
Esta URL muestra contenido casi idéntico a la categoría principal, pero es una URL nueva. Multiplica esto por todas las combinaciones posibles y habrás creado un laberinto con millones de páginas de bajo valor que ahogan a tu web.
Vamos a demostrarlo.
Paso 1: Aislar y contar las visitas de Googlebot
Vamos a nuestro compañero indispensable desde hoy, SEO Log File Analyser (primo hermano de Screaming Frog). Vamos a ver cuáles son las URLs que Googlebot visita con más frecuencia en tu web.
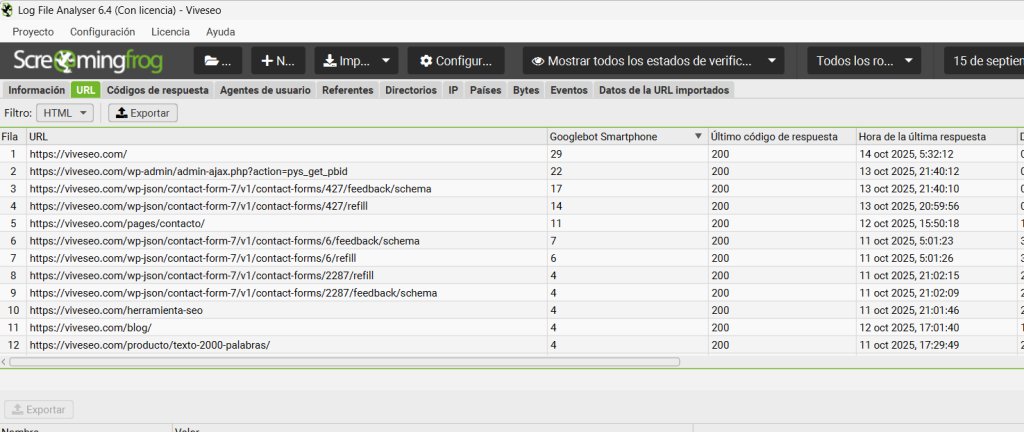
Paso 2: Afrontar la cruda realidad
Ahora mira el resultado. ¿Qué ves?
Si tu web está ENFERMA, verás algo así:
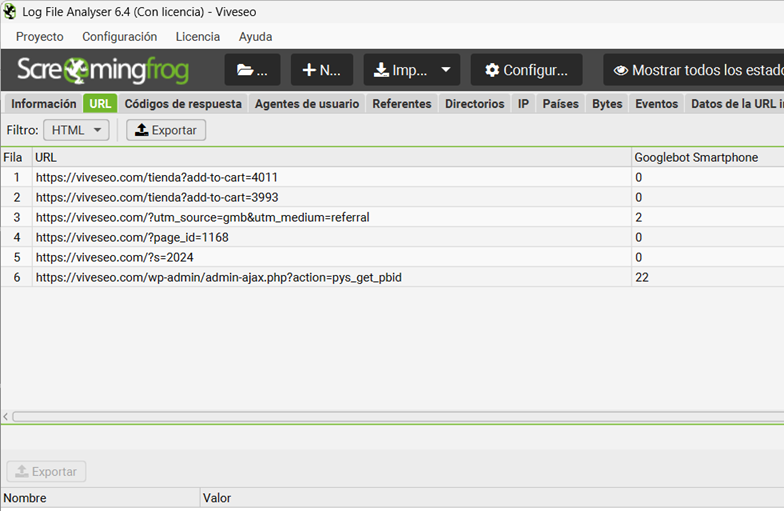
Si tu web está SANA, deberías ver esto:
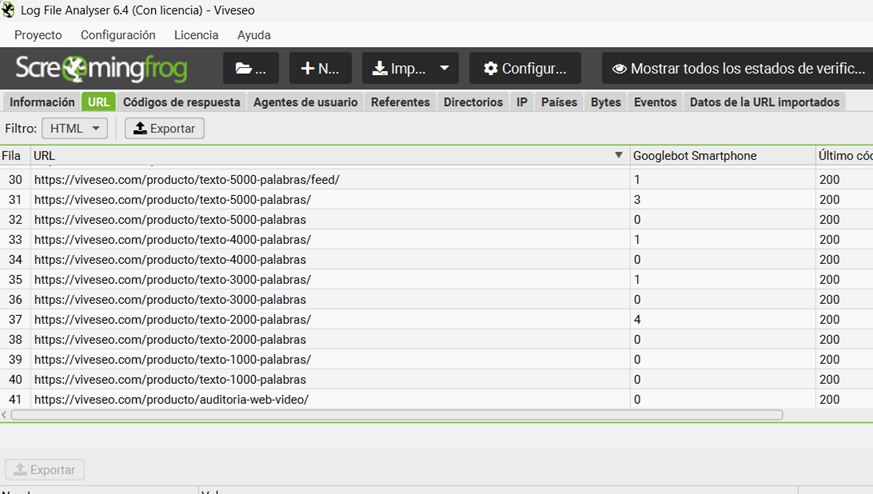
🪖 Historia de guerra:
Un cliente de moda online no entendía por qué sus nuevas colecciones tardaban un mes en indexarse. Ejecutamos un análisis de logs con SEO Log File Analyser y el resultado fue demoledor: el 90% del TOP 100 de URLs rastreadas por Googlebot contenían parámetros de filtros. Googlebot se pasaba el día «probándose» combinaciones de ropa en lugar de catalogar los productos nuevos.
La solución en 3 capas: recupera el control de tu rastreo
Si tus logs muestran el patrón enfermo, no entres en pánico. Vamos a solucionarlo con una estrategia de 3 capas, de la más rápida a la más robusta.
Capa 1: El Muro de Contención con robots.txt (La solución de emergencia)
Esta es la forma más rápida de detener la hemorragia. Le dices a Google, a las bravas, que no quieres que entre en ninguna URL que contenga parámetros.
Abre tu archivo robots.txt y añade esta regla:
User-agent: Googlebot
# Bloquea cualquier URL que contenga un '?'
Disallow: /*?*
En cuanto Googlebot vuelva a leer tu robots.txt, dejará de rastrear esas URLs. Contras: Es una solución «bruta». Si tienes algún parámetro que SÍ quieres que se rastree (por ejemplo, para paginación), te lo cargarás también. Una versión más fina sería:
# Bloquea solo los parámetros de filtros más comunes
Disallow: /*?color=*
Disallow: /*?talla=*
Disallow: /*?marca=*Capa 2: La señal de «No pasar» con rel="nofollow" (La solución inteligente)
Esta es la solución que ataca la raíz del problema. En lugar de prohibir la entrada a URLs que Google ya ha descubierto, evitamos que las descubra.
Habla con tu desarrollador para que añada el atributo rel="nofollow" a todos los enlaces de los filtros en tu web.
El código de un enlace de filtro pasaría de ser: <a href="/zapatillas?color=rojo">Rojo</a>
A ser: <a href="/zapatillas?color=rojo" rel="nofollow">Rojo</a>
Esto le da una señal clara a Google: «Puedes ver este enlace, los usuarios pueden usarlo, pero tú no lo sigas y no le traspases ninguna autoridad». Esto evita que Google se adentre en el laberinto.
Capa 3: El mapa del tesoro con rel="canonical" (La solución definitiva)
Esta es la capa que consolida todo y le dice a Google cuál es la única versión que importa.
- Página de categoría limpia: Tu URL de categoría principal (ej.
/zapatillas/) debe tener una etiqueta canonical que apunte a sí misma.<link rel="canonical" href="https://tudominio.com/zapatillas/" /> - Página de categoría con filtros: Cuando un usuario aplica un filtro (ej.
/zapatillas/?color=rojo), la página debe seguir teniendo la misma etiqueta canonical apuntando a la versión limpia.<link rel="canonical" href="https://tudominio.com/zapatillas/" />
Con esto, le estás diciendo a Google: «He visto que has llegado aquí a través de esta URL con filtros, pero la página original, la buena, la que tienes que indexar y a la que le tienes que dar toda la autoridad, es la que no tiene parámetros».
Y por supuesto, asegúrate de que tu sitemap.xml solo contiene las URLs canónicas y limpias. Nunca, jamás, incluyas una URL con parámetros de filtros en tu sitemap.




