
¿Qué es el TF IDF?
El TF IDF (Term Frequency-Inverse Document Frequency), es un método estadístico utilizado para evaluar la importancia de una palabra (keyword) en un documento, que es parte de una colección o corpus. Es una de las técnicas más utilizadas en la recuperación de información y en el análisis de texto para SEO (Search Engine Optimization).
Si conoces un poco la historia de Google, sabrás que al inicio de su historia, el algoritmo que hoy en día es tan avanzado funcionaba de forma muy similar a cómo la fórmula TF IDF se utiliza para encontrar los documentos más relevantes para una keyword concreta.
Aunque desde hace tiempo, el optimizar textos en base a una única keyword ha perdido sentido, buscamos más entidades, sí es cierto, que hacer este tipo de optimizaciones de contenidos en base a TF IDF (relevancia de una palabra en el texto) nos puede ayudar entre otras cosas a:
- Hacer nuestro contenido más amplio semánticamente, lo que a su vez ayudará a Google a entender mejor el contenido
- Aportar más valor a nuestros usuarios, ya que ampliamos las respuestas y conocimiento del tema principal que buscaban
Ojo: optimizar demasiado los textos o incluir de forma abusiva palabras claves puede darle señales a Google de keyword stuffing y tener el efecto contrario al deseado que es captar más tráfico desde Google.
Fórmulas para calcular TF IDF
Vamos a darle un vistazo a las fórmulas utilizadas para conocer las métricas de TF e IDF de un documento en relación a una palabra clave.
TF
Es la frecuencia con la que aparece una palabra en un documento específico. Si un documento tiene 100 palabras y una palabra aparece 5 veces, su TF es 5/100 = 0.05.

IDF
Es el logaritmo de la división entre el número total de documentos en el corpus y el número de documentos en los que aparece el término. La idea es que las palabras que aparecen en muchos documentos no son buenas discriminadoras y deben tener menos peso.

Combinación TF-IDF
Utilizado en el campo de la recuperación de información y el procesamiento de lenguaje natural como una forma de ponderar y evaluar la relevancia de los términos en documentos dentro de un conjunto de documentos, y es una parte fundamental de muchos algoritmos de búsqueda y clasificación de textos.
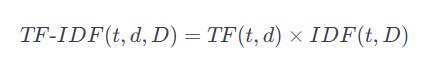
Cómo optimizar el TF IDF para optimizar los contenidos de mi web
Lo primero que tenemos que hacer es encontrar las keywords más relevantes para optimizar nuestro contenido, una url en concreto, recuerda que sólo puede resolver una determinada intención de búsqueda.
Usar la fórmula de TF IDF para analizar los contenidos de la competencia para una determinada keyword nos da idea de cómo la competencia utiliza esa keyword, sus variantes, keywords o entidades relacionadas o la densidad media de aparición de esa keyword en los contenidos que mejor posicionan.
Herramientas para calcular el TF IDF
Pero para conocer la densidad de la keyword en el contenido de los competidores puedes hacerlo a mano, con las fórmulas que hemos visto antes y tardar 2 semanas analizando contenidos…jajaj O usar alguna de las herramientas que existen, te hablo una gratuita y otra de pago con la que analizar el TF IDF y hacerlo en 5 minutos.
Dinorank
La suite de herramientas de Dean Romero, que cada vez va ampliando sus funcionalidades y mejorando su interfaz, que al principio era más ruda, tiene entre otras muchas opciones la posibilidad de calcular el TF IDF de urls que queramos optimizar.

Una opción que me gusta mucho de la nueva versión de Dinorank es la posibilidad de omitir determinadas palabras en el análisis de TF IDF, de esta forma no ensuciamos el informe final, que a veces puede contener demasiadas kws que no tienen nada que ver con lo que queremos optimizar. Otra de las opciones a destacar de la tool de Dinorank es que podemos descargar el informe en csv y trabajar con él de forma local o integrarlo en otras herramientas, trabajarlo con Google Sheets, etc…

Seobility
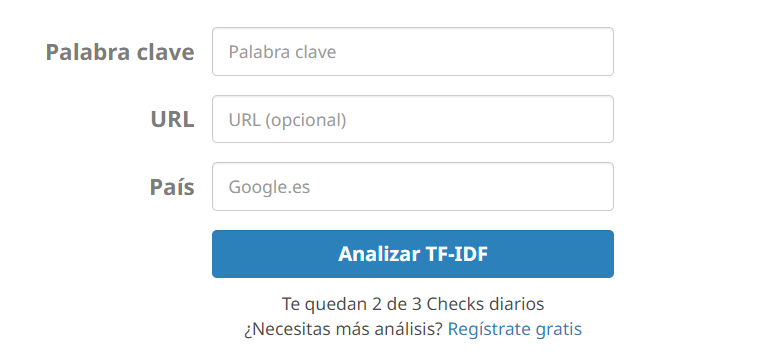
Seobility es una suite de herramientas SEO todo en uno, que personalmente no he probado por completo, pero sí su mini herramienta gratuita de análisis de TF IDF que nos permite para una URL y una keyword en concreto, saber el nivel de optimización (en base a esta fórmula de TF IDF) de nuestro contenido con respecto a la competencia.
Esta herramienta gratuita está limitada en el número de usos 3 diarios (aunque imagino que podrías resetearlo cambiando de IP), y es muy sencilla de usar, basta introducir, la URL, el país y la keyword en base a la que queremos optimizar el contenido.
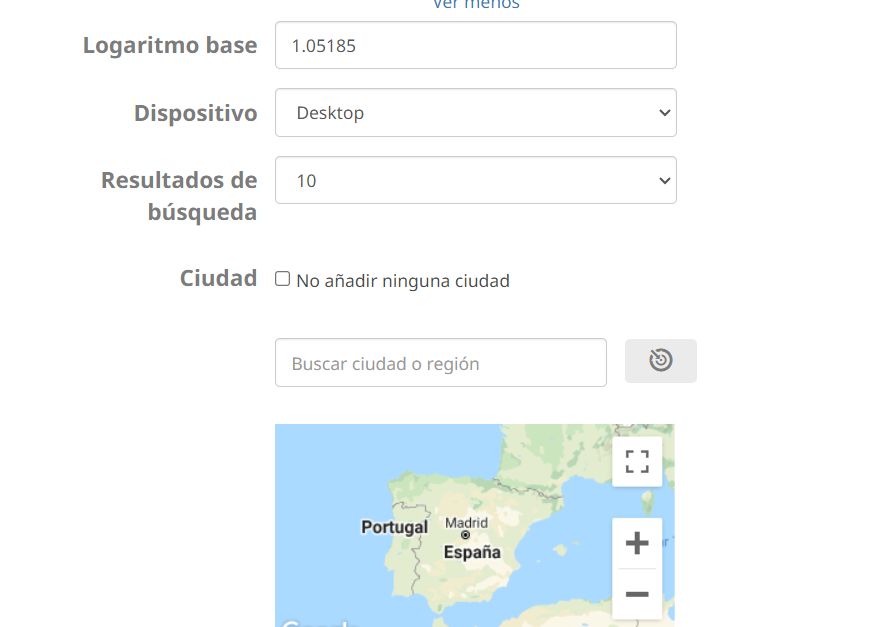
Aunque tienes la opción de configurar más opciones como Logaritmo (para calcular TF IDF y que la kw tenga más o menos peso), Dispositivo, Resultados de búsqueda (con los que comparará el contenido), Ciudad o Región…
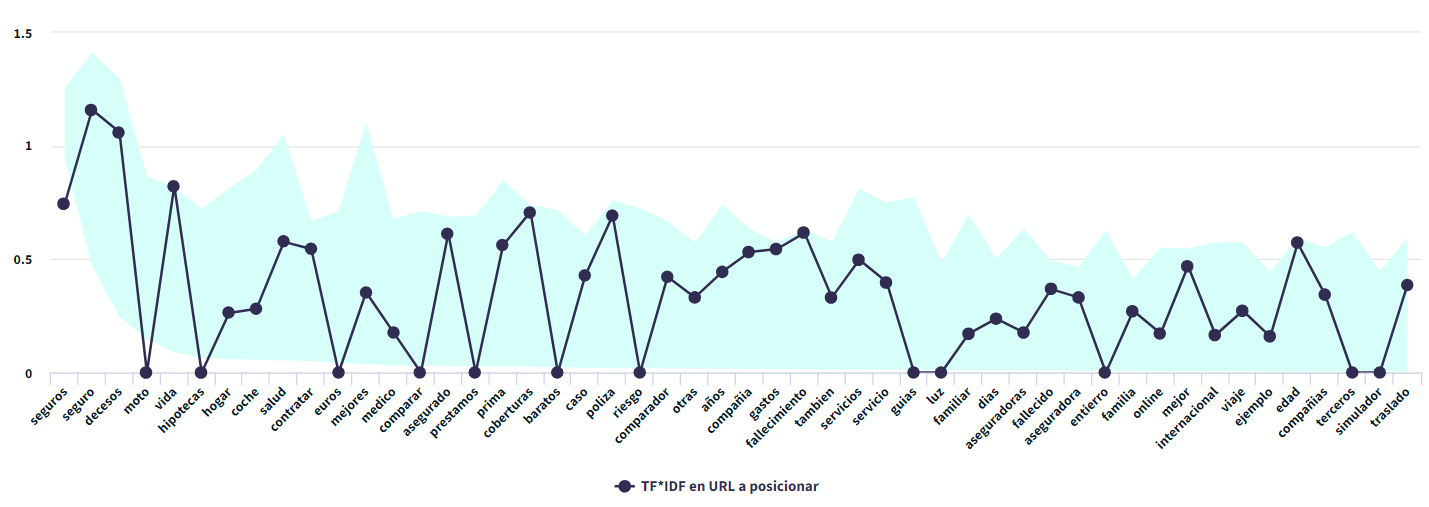
Una vez hecha la petición obtendrás una tabla muy similar a esta (con las keywords que hayas pedido, claro), en la que podemos ver:
- Media de la densidad de esa kw en el contenido de los competidores
- Máximo número de apariciones de la kw en el contenido de los competidores
- Y la densidad de la kw en nuestro propio contenido (URL que le hemos pasado) para comparar con la competencia


